Variance Reduction Techniques
The Bias-Variance Tradeoff
You may already be familiar with a bias-variance tradeoff scenario in machine learning -- our model is not producing desirable training error, so we choose to increase the complexity to better fit the training data. However, in doing so we may find that we "overfit" the model to the training data and create a prediction model that is biased to the details and minutae of the training data. When we apply the model to test data that it has not previously seen, it performs more poorly than our simpler model.
This is commonly referred to as "overfitting" and is an example of a biased model. As we increase the complexity of our model, we are trading the magnitude of prediction error to the test data (variance) for bias to the training data itself.
The bias-variance tradeoff we see in variance reduction techniques for SGD algorithms is fundamentally different than our familiar example.
Model complexity bias-variance tradeoffs can affect the error in predictions by the model itself -- but in the context of stochastic optimizaiton, bias and variance can impact error in parameter updates.
The issue with this variance in general ends up being the rate at which we converge, or whether we converge at all. Variance that overwhelms the steps, it can adversely impact the rate at which we converge to an acceptable solution, and if our algorithm takes too long to execute, we have defeated the purpose of using stochastic methods. In all, our goal becomes finding a balance of the computational advantages of stochastic processes while keeping variance (and as we will see, bias) under control in order to reap the advantages of faster algorithms.
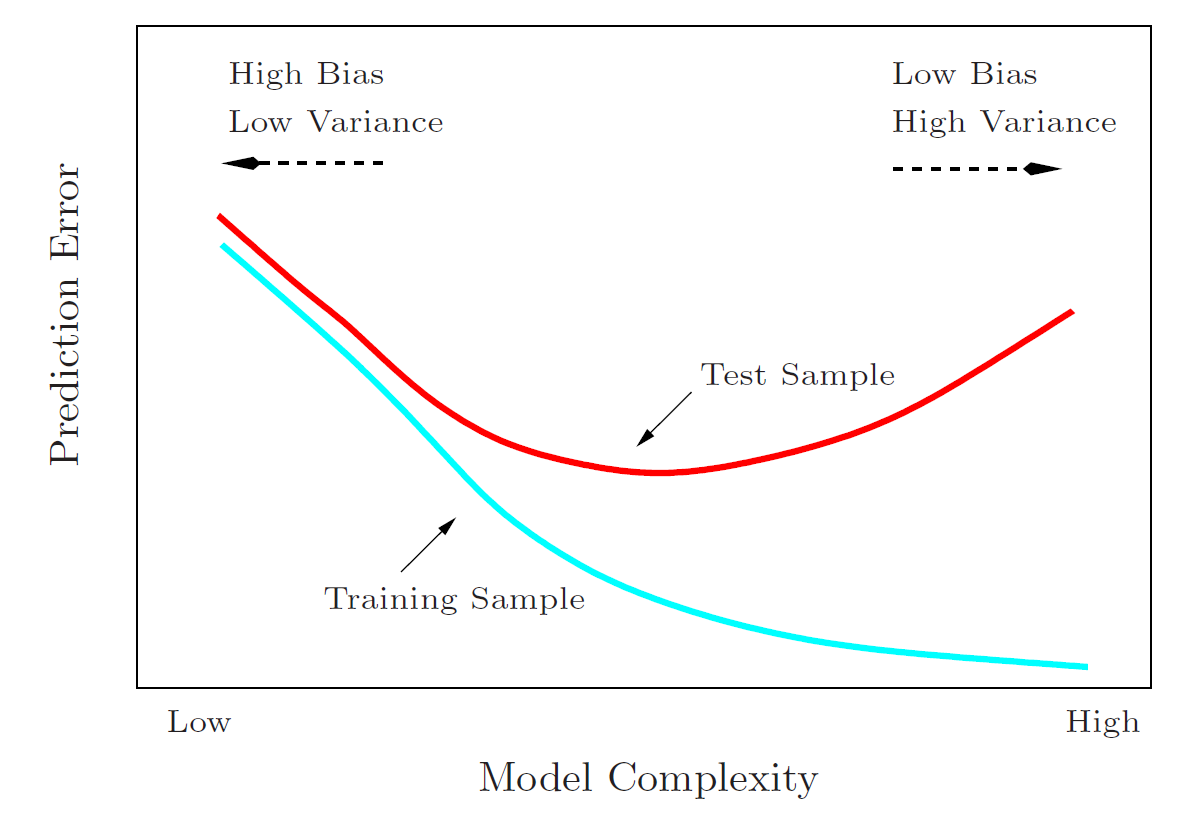
Image from Hastie et al. (2004) p.38, a general illustration of the bias-variance tradeoff
MSE, Variance and Bias
Before we get into some techniques that can address variance in stochastic descent, we need to observe one of the core principles of statistical anlysis.
Part of our due diligence in statistics is to analyze the quality of an esimator. To quantify the accuracy of an estimator , we measure the error of the estimator compared to the true value of the parameter it is estimating by using Mean Squared Error (MSE).
MSE is a quantity defined as the expected value of the square difference between the parameter estimate and the true parameter value. Skipping some steps in between, it can be decomposed into both a variance component and a bias component (a link to a helpful video about MSE).
In statistics, we often measure the quality of an estimator by whether it is both unbiased and consistent. We won't dive into consistency of estimators further here (see appendix for some detail), but we do want to take note that in general, unbiased estimators are preferred estimators to those that are biased in some way. In terms of MSE, if our estimator is unbiased, then its MSE is equal to its variance.
In the previous section some examples of an unbiased estimator.
For example, we assume our conditional estimator of the approximation error for a gradient, is unbiased, i.e. , where . So, the MSE for the estimator is only its variance.
We showed , so the MSE of , the estimate of stochastic gradient estimation error for a given , is the following.
which is bounded by a constant variance term.
It is important to be cognizant of MSE as the measure for error of an estimator rather than just the variance. We don't just care about variance -- bias is a nontrivial and undesirable quantity if we are not careful.
As we explore variance reduction techniques, we will see that if we attempt to curb error due to variance but do not reduce overall MSE of the estimator in doing so, that MSE information is only "transferred" to the bias component. Compounding effects of bias in recursive descent algorithms can become especially problematic, so as we continue, we will give special attention to ensuring we also take it into account.
Minibatch SGD
Since variance in the algorithm's steps is a consequence of using estimates of the full gradient, it is pragmatic to utilize improved approximations. One natural statistical approach to improving an approximation is simple, we should use more data. We can do so by taking random batch samples of the full data -- minibatches.
Minibatches are an important variance-reduction technique that are commonly seen in the class of gradient descent algorithms. Rather than sampling random individual gradients from the full gradient at each step, we can improve our gradient approximation by sampling a random subset where and modify the SGD algorithm to average the "minibatches".
See appendix for example calculation details
We first take the conditional expectation modified from SGD. Note, as with SGD the gradient estimate is unbiased .
NOTE
The above calculation uses the identity to derive inequality.*
We can reduce the variance bound by a factor of batch size be . Since the estimator is unbiased, we do not need to be concerned with mere displacement of MSE a bias term. Intuitively we can make sense of this since we are using more information for each gradient calculation, and thus we get a better approximation of the gradient at each step . Note here also that this result does not require a diminishing learning rate, so it can be applied to gradient descent algorithms with constant or adaptive learning rates.
The tradeoff here, though, is a more expensive gradient computation by a factor of at each timestep. No free lunch! A convergence analysis will show that minibatch SGD converges at a rate , which is the same as SGD but at greater expense computationally due to the batch size. It's largely considered a compromise between SGD and regular gradient descent.
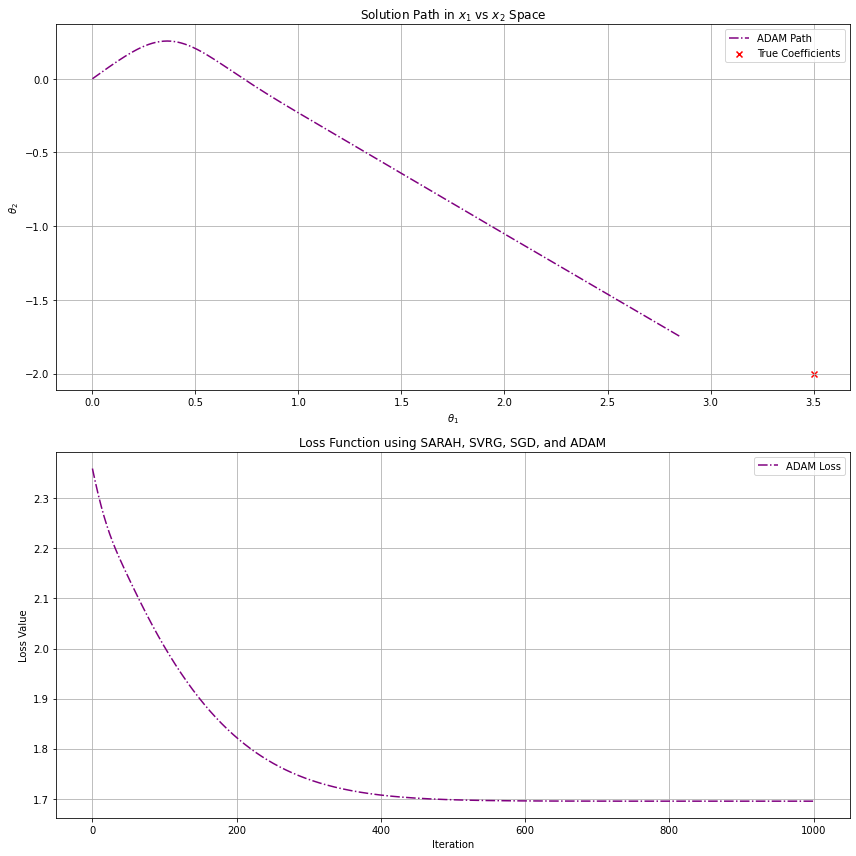
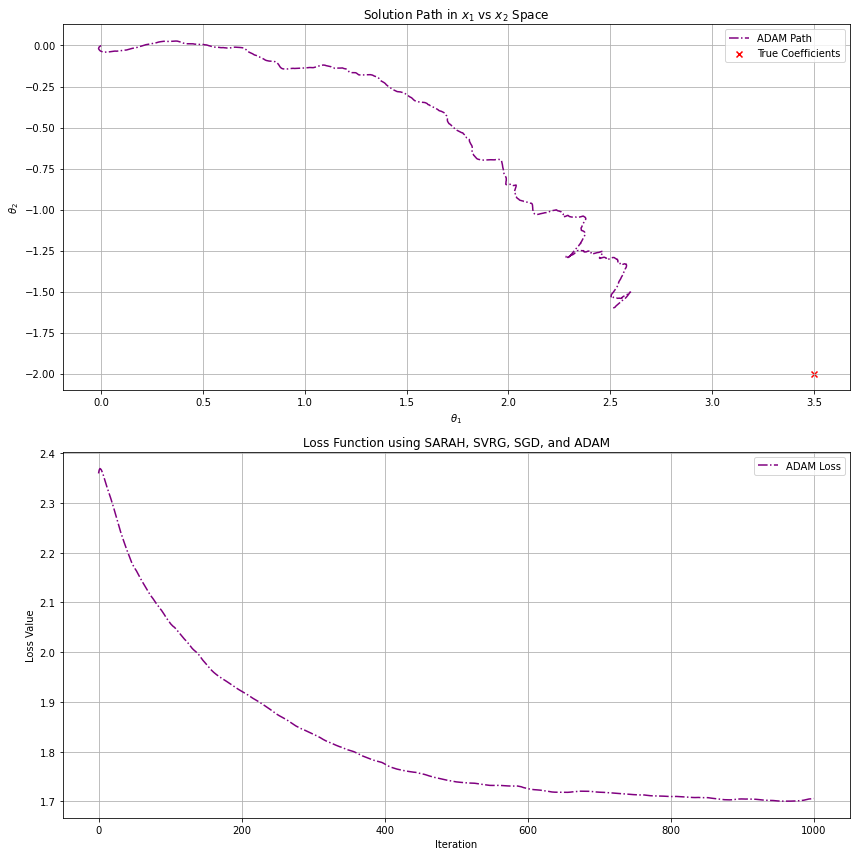
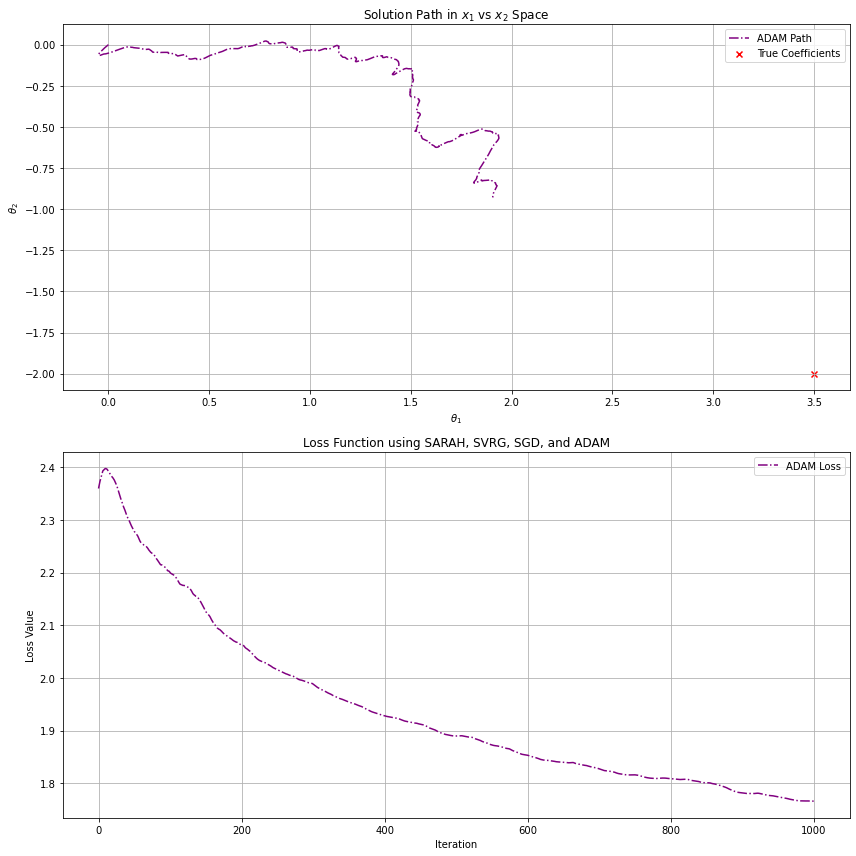
The ADAM optimizer, which we will see in greater detail later, utilizes batch gradients. We are fitting to the same correlated noise data from above, which has samples and two features and . The above graphs demonstrate the effects of variance reduction for increasing batch sizes. The first plot uses a batch size of (which is essentially regular gradient descent with ADAM's boost), the second , and the last . Clearly, we get closest to our optimal solution using bigger batches to reduce variance in the steps, but what this does not capture is additional computational cost for each step. Ultimately, we tune parameters like batch size to find a balance between performance and results.
Stochastic Average Gradient (SAG) and SAGA
SAG and SAGA utilize important variance reduction techniques and are often treated as benchmarks for comparison with stochastic and batch gradient descent algorithms. Minibatches serve well in reducing variance, however as we increase the batch size, we are also increasing the per-iteration computational cost; as approaches , we end up back where we started with regular gradient descent. Our goal is to achieve a convergence rate of with a cost of one gradient per iteration, motivating SAG.
Stochastic Average Gradient (SAG)
The framework for SAG uses gradient descent in the following form, taking the average gradient at each iteration.
where .
For SAG, we will update only one gradient at step , for uniformly random chosen , and keep all other at their previous value.
To accomplish this, the procedure maintains a table containing , . This table does require additional storage computationally proportional to the size of the data.
We first initialize and set and for all .
At each step we select uniformly at random and update our individual gradient, keeping all other values of the same.
We then perform the per iteration update.
We now have a new estimator for the gradient which we will call , which can be written as the following.
If we set and , noting that , can be rewritten as the following.
As with our previous analysis of estimators, we take the expectation of ,
Our expectation for our estimator is nonzero, so our gradient estimator is biased!
Omitting the details, SAG can be shown to converge under our usual convexity and Lipschitz continuity for the gradient per the following. For and and the intialization,
we achieve the following convergence.
Comparing directly to SGD:
- This is the desired (more accurately ), which is overall an improvement as compared to SGD
- Converges with constant learning rate
- SAG does not require the assumption of conditional boundedness of the variance ()
- BUT this algorithm is biased
- It's a drawback computationally to need to store a gradient table
SAGA
The SAGA algorithm is only a slightly modified version of SAG, with the only difference being a modification of the gradient estimate itself. We will still maintain our table of gradients, use the same initialization procedure, and pick/replace a random gradient in the same fashion.
Instead, however, of the SAG gradient estimate , we use the following gradient estimate for SAGA.
So, our per iteration updates are of the following form.
SAGA can be shown to have the same convergence , but can use a slightly better learning rate . It also does not require the bound on conditional variance. The most stark difference with SAGA vs. SAG is that SAGA is unbiased. It still has the less than desirable need to store a gradient table.
Using the same definition for random varables and as before, we have the following.
So, is an unbiased estimator for the gradient and it follows that the bias term for this method.
SAG & SAGA Variance comparison
Recall the gradient estimates for each.
SAG
SAGA
For and where and are correlated, we have the general form.
Where for SAGA and for SAG.
Taking the variance, we have the following.
So, we can compare the methods.
SAGA's modified algorithm makes the iterations unbiased, however by doing so we increase variance in the steps. The SAG/SAGA has tradeoffs with bias and variance, but ultimately both converge at the same rate. In terms of MSE, this means we may not have an obvious advantage for either method other than the faster learning rate of SAGA.
Other Common Variance Reduction Techniques
We have covered some basics of stochastic gradient descent algortihms, as well as some basic approaches to variance reduction, but I also wanted to include some supplemental material for further reading on the basics of the topics. If you are interested in learning more about some common techniques, I recommend this paper on variance reduction techniques in machine learning (Gower et al., 2020).